

In our previous blog note, we discussed a methodical approach to converting call center audio recordings into text on an industrial scale. This capability is a game changer for companies in many different industries since it allows them to obtain relevant customer data (customer satisfaction, churn reason, etc.) that only a few years ago was inaccessible and used to take a lot of human effort and resources to unlock.
One of the key points to be compliant with current regulations is the importance of removing sensitive information about the users from the datasets used with analytical proposes. This sensitive information is what we call PII (Personal Identifiable Information). If this data is not properly handled or removed from the datasets used to extract users’ insights, it may result in costly lawsuits against businesses. This article will discuss different techniques to remove PII data from audio conversations previously converted to text “dialogs.”
Different techniques to remove PII information
Plenty of tools are available on the market to remove PII information. All these tools perform the same function but with different techniques under the hood, varied results, and varied costs. The core functionality is to take a text input that “contains” sensitive information and return an anonymized text. These tools also allow the user to define which PII attributes should be considered in the scope for anonymization (first names, surnames, phone numbers, emails, IP, etc.). Figure 1 shows a graphical representation of how a PII removal tool should work.
Figure 1: an example of how a PII removal tool works.
Until recently the best practice was to utilize a rules-based system to look for PII attributes, tag/treat those attributes as early as possible in the data ingestion processes that moved data into the Enterprise for processing. All of this is to protect customers’ confidentiality and reduce other types of business risks.
Before modern machine learning systems, rule-based systems were the standard way to anonymize data. These systems use a set of rules to define if a word belongs to a certain entity type (in this case, these entities can be names, email addresses, phone numbers, etc.) and mask the input text based on these rules. However, this kind of solution implementation has limitations and maintenance costs as new attributes come into the business:
- Rigidness: the rule-based systems will catch only the entities’ values that the rules defined by the user comprehend. In other words, they are rigid. Because of that, if a new entity value doesn’t fulfill one of the predefined rules it won’t be caught by the system. For example, if the user tries to catch names by using a rule (a fixed list of names), if an example with a name that isn’t included in the rule’s list, then the system won’t mask that new value as a name.
- Contextual limitations: some names can have another meaning (being a noun or an adjective) depending on the context. For example, Rose is cleaning the vase. Depending on the context, a Rose can be a name or a noun (the flower). These kinds of cases take a lot of work to catch for rule-based systems.
As Large Language Models are becoming more widely available and affordable to use, modern AI-based PII systems tackle these problems by taking into account the labels that may accompany the PII attribute and even the context where the PII attribute(s) are embedded. Because of that, their accuracy in finding and mapping these PII entities is much more accurate than the old-fashioned systems.
In this article, we will evaluate two different approaches to finding PII fields: classic entity recognition systems and LLM-based systems. The entity recognition systems look at a word context to define whether that world is a PII field or not. In this case, the tool used was Google DLP (Data Loss Prevention). This tool has an entity recognition model that recognizes up to 150 different types of fields with sensitive information. On the other hand, the LLM-based systems use an LLM and a prompt designed for the PII recognition task and mask the PII values detected in the piece of text given as input. One of the key advantages of this approach is that it allows the user to define custom PII fields to be masked (outside, for example, the 150 default ones available in Google DLP) by simply modifying the prompt used for this task. Customization is the key advantage of this approach.
The benchmark
For this benchmark, we used the pii-masking-200k dataset. This is a public dataset that contains 200,000 pieces of text with PII data labeled. This dataset contains up to 54 different PII categories and the pieces of text are in four different languages (English, French, German, and Italian). It provides a comprehensive source of truth for model comparison since it contains many different PII categories in many languages.
For this particular benchmark, we focused on five PII categories: first name, last name, email address, phone number, and address. This constraint reduced the sample size to 3826 elements. For each estimator and each PII category, we quantified the number of times when that category was correctly and incorrectly found. We considered that a piece of text is incorrectly labeled when the model doesn’t assign the expected label and when the model assigns an incorrect label (i.e.: an estimator masks Mouriño Street as [LAST_NAME] Street).
As we mentioned before, we used Google DLP, Data Loss Prevention, to represent the classical entity recognition models. For the LLM-based approach, we tested many different models using the same prompt. These models are GPT 3.5, GPT 4, GPT 4o (OpenAI), Anthropic Claude v2 (AWS), Gemini 1.5 Flash, and text-unicorn@001 (Google Cloud). Since some improvement can be obtained by customizing the prompt for each model, the idea behind this experiment is to separate the poor-performing LLMs from the high-performers. The obtained results are displayed in Table 1. The detailed results by each category can be found in Table 2 to Table 8 (see the appendix).
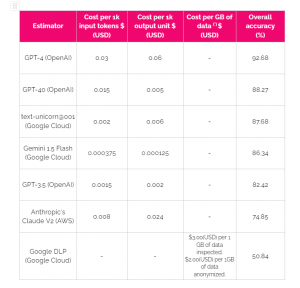
Table 1 – benchmark results summary. The cost data was updated on 2024-06-26. OpenAI and AWS models’ costs are expressed per 1K tokens whereas for Google models are per 1K characters
The main takeaways from this benchmark are:
- The estimator with the best performance is the GPT-4-based system, and the one with the worst performance is Google DLP.
- If we take into account the price, the system with the best price-performance trade-off is the Gemini 1.5 Flash-based system. This is because it costs 10 times less than the GPT-4-based one and it has a performance only 6% lower if we consider the overall accuracy.
- For Google DLP, it’s particularly surprising that it is unable to catch any address value. By doing a deep dive into the examples, we found out that it tends to confuse surnames as addresses (i.e.: Johnson Street is anonymized as [SURNAME] Street).
- All the systems have a great performance for email address (the model with the worst performance, GPT-3.5, has a 94.13% accuracy for this label) recognition.
Choosing the Right PII Removal Method
In this article, we compared several estimators to find PII attributes in text and to remove them. This is a crucial step in any call center analytics system (and, in general, in any system that works with text data with sensitive information) since it allows the removal of users’ personal information.
We observed an important variability in the performance of the two solution approaches and across the different LLMs.
If we look only at the overall accuracy, the best performer estimator is the GPT-4-based system (OpenAI), and the worst performer is Google DLP (Google Cloud). However, if we include the cost in the equation, the best option by far is the Gemini 1.5 Flash-based system (Google Cloud Platform). This anonymization system has an overall accuracy comparable to the GPT-4-based system but for a fraction of the cost (10 times less).
PII identification, tagging, and treatment performance should not be forgotten about. Cloud and service accounts require that quotas be adjusted according to performance demands for the given use cases and volumetrics being targeted.
For each particular use case, it is important to take into account the specific requirements for it. Because of that, it is important to assess the required accuracy to be compliant with the product requirements, the cost that this accuracy implies, and accepted latency (if the system will be a stream system, then the latency will be an important factor in choosing the best-suited estimator for the use case).
The latest relevant aspect to point out is that there is no perfect model. This idea is crucial for PII remotion use cases because, in some situations, very demanding standards regarding data anonymization must be fulfilled. Because of that, to be fully sure that the system does its trick in the way it should, from Making Science we always recommend keeping the human in the loop. The presence of human validation of the output generated by the LLM-based system will ensure that the solution fulfills the minimum requirements regarding PII entities’ remotion.
Accuracy by label by model appendix
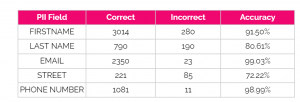
Table 2 – GPT-4 accuracy by PII field
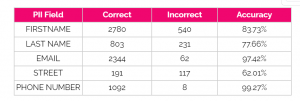
Table 3 – GPT-4o accuracy by PII field
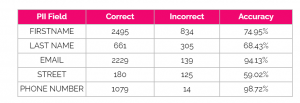
Table 4 – GPT-3.5 accuracy by PII field
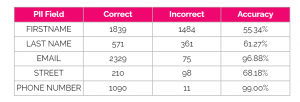
Table 5 – Anthropics’s Claude v2 accuracy by PII field
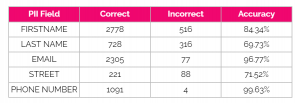
Table 6 – text-unicorn@001 accuracy by PII field
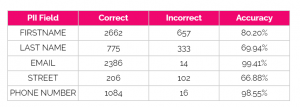
Table 7 – Gemini Flash 1.5 accuracy by PII field
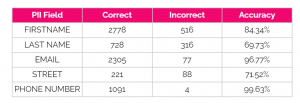
Table 8 – test-unicorn@001 accuracy by PII field
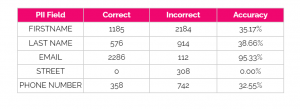
Table 9 – Google DLP accuracy by PII field
Conclusion
This exploration into PII removal from call center transcripts reveals a critical takeaway for businesses: achieving both accuracy and cost-efficiency is possible. While the advanced capabilities of GPT-4 delivered accuracy, the cost factor cannot be ignored. This is where Gemini 1.5 Flash shines, providing top-notch performance at a significantly lower cost, making it a compelling solution for organizations of all sizes.
At Making Science, we understand the importance of balancing powerful AI solutions with robust security measures. We are committed to helping businesses unlock the full potential of their call center data while upholding the highest ethical and security standards. Our team of experts can help you develop and implement a tailored PII removal strategy that leverages the latest technologies, including Gemini 1.5 Flash, while ensuring complete and reliable data anonymization. Contact us to learn how we can tailor a solution to your specific needs.




 Cookie configuration
Cookie configuration